Python
[Python] nn.Embedding 사용해보기
teamnova
2025. 8. 7. 18:54
728x90
이번 포스팅에서는 PyTorch의 nn.Embedding 모듈을 사용하여 정수 인덱스를 임베딩 벡터로 변환해보도록 하겠습니다.
nn.Embedding은 텍스트 처리에서 자주 사용되는 모듈입니다.
앞으로 자연어처리(NLP), 감정 분석, TTS(음성 합성) 등 다양한 딥러닝 프로젝트에 활용될 수 있습니다.
우선 터미널에서 PyTorch를 다운로드 받아줍니다.
> pip install torch
전체 코드입니다.
embedding_example.py
import torch
import torch.nn as nn
# 임베딩 정의: 총 10개의 단어, 각 단어를 3차원 벡터로 임베딩
embedding = nn.Embedding(num_embeddings=10, embedding_dim=3)
# 임베딩할 입력 (정수 인덱스): 예를 들어 문장에서 [2, 5, 8] 이라는 단어들이 있다고 가정
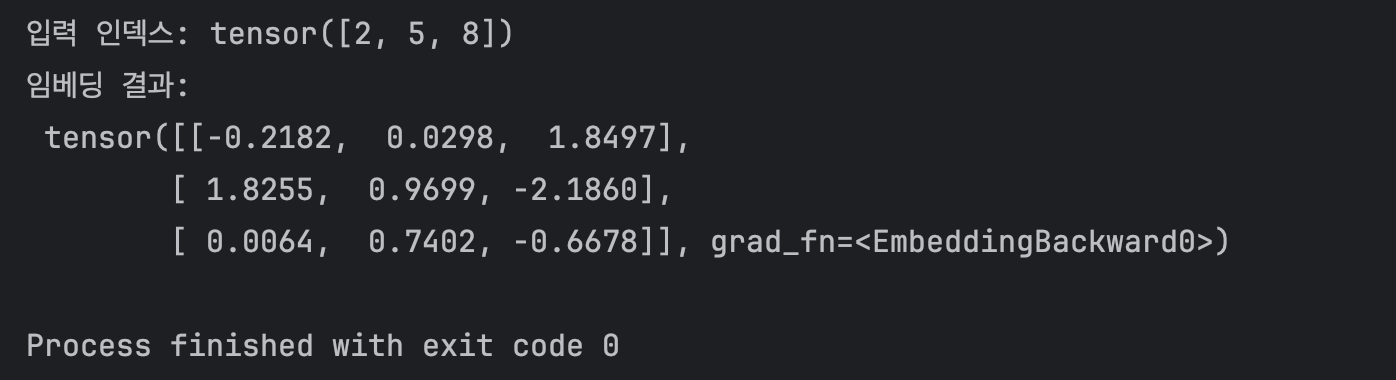
input_ids = torch.LongTensor([2, 5, 8])
# 임베딩 수행
output = embedding(input_ids)
print("입력 인덱스:", input_ids)
print("임베딩 결과:\n", output)
실행 결과입니다.