자연어 처리에서 크롤링 등으로 얻어낸 코퍼스 데이터가 필요에 맞게 전처리되지 않은 상태라면, 해당 데이터를 사용하고자하는 용도에 맞게 토큰화(tokenization) & 정제(cleaning) & 정규화(normalization)하는 일을 하게 됩니다. 이번에는 그 중에서도 토큰화를 하는 방법들에 대해 작성해 보겠습니다.
토큰 이란?
토큰(Token) 화폐 대신 사용할 수 있는 동전처럼 생긴 주조물을 말한다. 어휘분석의 단위를 가리키는 컴퓨터 용어이기도 하다.
자연어를 컴퓨터가 이해할 수 있는 언어로 만들기 위해 단어나 문장 단위로 쪼개는 작업이 필요한데 이런 토큰화를 수행하는 방법에는 다양한 방법이 있지만
일반적인 방법론은 공백문자를 기준으로 단어를 분리하는것인데 이를 토큰화(tokenization)라고 합니다.
하지만 공백 문자만을 기준으로 토큰화를 수행하면, 문장 부호나 특수 문자 등이 포함된 토큰을 처리할 수 없기 때문에 정확도가 떨어질 수 있습니다.
따라서 , 보다 정확한 토큰화를 위해서는 여러가지 방법을 적용해야 합니다.
예를 들어, 영어의 경우에는 단어를 분리하는 것이 어려운 경우가 많음 "don't"이나 "I'll"과 같은 축약형이나, "U.S.A."와 같은 약어 등은 분리하여 처리해야 합니다. 이를 처리하기 위해서는 정규표현식이나, 구분자 기반 토큰화 방법을 사용합니다.
오늘은 NLTK에서 제공하는 토큰화 도구 중 word_tokenize와 WordPunctTokenizer를 사용해서 토큰화 를 진행해 보겠습니다.
실습은 Jupyter notebook 에서 진행 하였습니다.
우선 NLTK 를 설치해 주겠습니다.
pip install nltk이후 필요한 도구들을 가져오겠습니다.
from nltk.tokenize import word_tokenize
from nltk.tokenize import WordPunctTokenizer
from tensorflow.keras.preprocessing.text import text_to_word_sequence
이제 한 문장을 두개의 도구를 사용해 토큰화를 진행해 보겠습니다.
test_seq = "Don't be fooled by the dark sounding name, Mr. Jone's Orphanage is as cheery as cheery goes for a pastry shop."
print('단어 토큰화1 :',word_tokenize(test_seq))
print('단어 토큰화2 :',WordPunctTokenizer().tokenize(test_seq))코드를 실행시키면 다음과 같은 결과를 얻을 수 있습니다.

비교해 보면 word_tokenize는 Don't를 Do와 n't로 분리하였으며, 반면 Jone's는 Jone과 's로 분리한 것을 확인할 수 있습니다.
WordPunctTokenizer는 앞서 확인했던 word_tokenize와는 달리 Don't를 Don과 '와 t로 분리하였으며, 이와 마찬가지로 Jone's를 Jone과 '와 s로 분리한 것을 확인할 수 있습니다.
이처럼 언어를 처리하는 토큰화 방식에는 약간의 특징들이 존재하고 이중 어떤 토큰화 방식을 선택하는지는 데이터의 용도에 영향을 끼치지 않는 선에서 개발자 스스로 선택하면 됩니다.
마지막으로 케라스 에서 제공하는 토큰화 도구로서 text_to_word_sequence를 사용한 결과를 보고 마무리 하도록 하겠습니다.
print('단어 토큰화3 :',text_to_word_sequence(test_seq))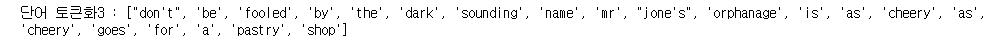
케라스의 경우 대문자를 소문자로 바꾸어 주고 어퍼스트로피 의 구분을 하지 않는것을 볼 수 있습니다.
'Python' 카테고리의 다른 글
| [Python]Python에서 데이터 프레임을 이용하여 파이그래프 그리기 (0) | 2023.07.05 |
|---|---|
| [Python] openpyxl 라이브러리로 xlsx 파일 쓰거나 읽기 (0) | 2023.06.30 |
| [Python] Raspberry Pi 4 카메라로 영상 스트리밍 하기 (0) | 2023.06.15 |
| [Python] Json 형태의 데이터 다루기 (0) | 2023.06.13 |
| [Python] schedule 라이브러리로 정해진 시간에 코드 자동 실행하기 (0) | 2023.06.06 |



