오늘은 pandas.concat() 함수를 사용하여 데이터프레임들을 합치는 방법을 알아보겠습니다.
pandas.concat() 함수는 기본적으로 시리즈나 데이터프레임과 같은 판다스 객체들을 특정 방향(축)으로 이어붙이는 함수입니다.
문법은 다음과 같습니다.
pandas.concat(objs, *, axis=0, join='outer', ignore_index=False, keys=None,
levels=None, names=None, verify_integrity=False, sort=False, copy=True)아래는 자주 사용되는 파라미터들에 대한 설명입니다.
- objs : a sequence or mapping of Series or DataFrame objects
- 이어붙일 시리즈/데이터프레임들을 입력합니다.
- 예) 데이터프레임 df1과 df1을 합치려면 [df1, df2] 과 같은 형태로 입력합니다.
- axis : {0/’index’, 1/’columns’}, default 0
- 어떤 축을 기준으로 연결할지를 말합니다. 0이면 행을, 1이면 열을 기준으로 연결하게 됩니다.
- 디폴트는 0, 즉 행을 기준으로 연결합니다.
- join : {‘inner’, ‘outer’}, default ‘outer’
- 연결할 기준축이 아닌 다른 축의 인덱스를 처리하는 방법을 말합니다.
- inner, outer 방식이 있으며, 디폴트는 outer 입니다.
- ignore_index : bool, default False
- 연결할 때 기존의 인덱스를 사용할지 여부를 말합니다.
- 디폴트는 False이며, 만약 ignore_index=True 라면 기존의 인덱스가 아닌 새로 부여한 인덱스(0, 1, 2, ... , n-1)로 인덱스를 다시 세팅하게 됩니다.
그 외의 파라미터에 대한 설명은 https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.concat.html 를 참고하시면 되겠습니다.
간단한 예제를 통해 위 함수의 사용법에 대해 알아보겠습니다.
먼저 데이터프레임 2개를 생성하겠습니다.
import pandas as pd
df1 = pd.DataFrame({'name':['A','B','C','D'],
'age':[18,30,25,42],
'city':['Seoul','Incheon','Seoul','Busan']}, index=[0,1,2,3])
df2 = pd.DataFrame({'name':['B','C','D','E'],
'age':[30,25,42,11],
'city':['Incheon','Seoul','Busan','Suwon'],
'height':[150, 170, 180, 135]}, index=[1,2,3,4])df1과 df2는 각각 다음과 같습니다.

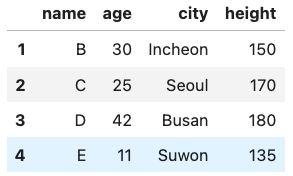
먼저, 다른 파라미터 추가 없이 두 데이터프레임을 합쳐보겠습니다.
concat1 = pd.concat([df1, df2])concat1 이라는 데이터프레임은 다음과 같습니다.
axis 값을 설정하지 않았기 때문에 디폴트값인 0이 사용되었고,
axis=0 은 행을 기준으로, 즉 위아래로 두 데이터프레임을 이어붙이게 되므로 다음과 같은 결과가 나왔습니다.
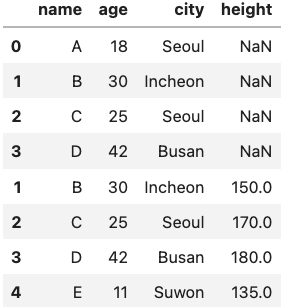
이 때, df1 에는 'height' 컬럼이 없으므로 NaN 값이 채워진 것을 확인할 수 있습니다.
concat1의 인덱스 번호는 0,1,2,3,1,2,3,4 로, df1과 df2의 인덱스번호가 그대로 사용되었습니다.
만약 새로운 인덱스 번호를 부여하고 싶다면 ignore_index=True 파라미터를 입력하면 됩니다.
concat2 = pd.concat([df1, df2], ignore_index=True)concat2는 다음과 같이 새롭게 인덱스 번호가 설정되었음을 확인할 수 있습니다.

이번에는 axis=1 값을 통해 열방향(좌우)으로 합쳐보겠습니다.
concat3 = pd.concat([df1, df2], axis=1)
df1의 인덱스는 0,1,2,3이고, df2의 인덱스는 1,2,3,4 이므로 그에 맞게 이어붙여졌습니다.
df1에는 4행이 없고, df2에는 0행이 없으므로 해당 데이터는 NaN 값으로 채워진 것을 확인할 수 있습니다.
그리고 join 옵션을 따로 설정하지 않았기 때문에 디폴트 값인 'outer'이 설정되어서 위와 같은 결과가 나왔습니다.
만약 join='inner'로 설정을 하면 교집합에 해당하는 부분만 이어붙이게 됩니다.
concat4 = pd.concat([df1, df2], axis=1, join='inner')
df1, df2에 모두 존재하는 행 인덱스는 1, 2, 3이기 때문에 concat4 는 위와 같이 합쳐진 것을 확인할 수 있습니다.
이상으로 pandas 의 concat() 함수가 무엇인지, 그리고 그 사용법에 대해서 간단하게 알아보았습니다.
'Python' 카테고리의 다른 글
| [Python] Tensorflow로 나만의 데이터셋 만들기 (0) | 2023.01.18 |
|---|---|
| [Python] pickle 모듈을 사용해서 직렬화, 역직렬화 하기 (0) | 2023.01.08 |
| [Python] Tensorflow 분류모델에서 훈련결과 추론해보기 (0) | 2023.01.06 |
| [Python] Colab을 사용하는 법 & 구글 드라이브 연동하기 (0) | 2023.01.03 |
| [ Python ] csv 파일을 불러와서 판다스 데이터프레임 생성하기 (0) | 2022.12.29 |



